
In the digital era, data has become a valuable asset for companies, but it is often scattered across various systems, formats, and platforms, making it difficult to manage. Virtualization offers a solution by enabling access and integration of data from multiple sources without the need for relocation or duplication.
This technology creates an access layer that simplifies data management, allowing real-time analysis without altering the original sources.
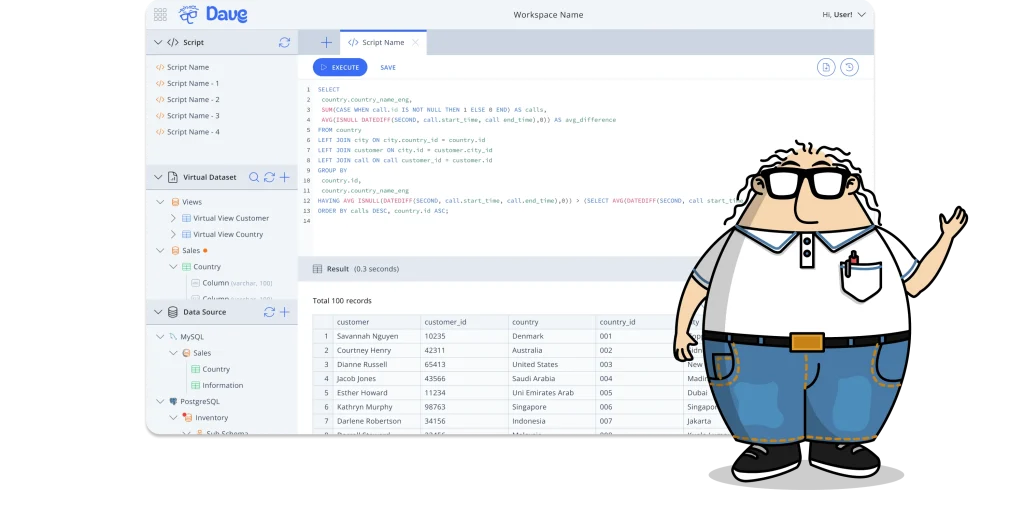
Use Case: Challenges Faced by Data Analysts in Data Integration
A Data Analyst at a retail company is tasked with analyzing sales trends. The data needed comes from various sources:
- MySQL Database for offline store transaction data
- Google BigQuery for e-commerce data
- CSV files from monthly reports sent by the finance team
Before using virtualization, the team had to manually download and merge this data, which was time-consuming and prone to errors. With virtualization, the Data Analyst can access all this data in a unified view without relocating it, enabling faster and more efficient real-time analysis.
Read Also : Supported data sources in Data Virtualization
Supported Data Sources in Virtualization
One of the key advantages of virtualization is its ability to connect with various data sources. Here are some of the data types that this technology can support:
Diverse Data Sources
Virtualization can connect various types of databases, both relational and non-relational, including:
- Relational Databases: Such as Oracle, MySQL, PostgreSQL, and Microsoft SQL Server.
- NoSQL Databases: Such as MongoDB and Cassandra, used for handling semi-structured and unstructured data.
- Cloud Data: Cloud-based data storage services like Google BigQuery, Amazon Redshift, and Snowflake.
Various File Formats
Besides databases, virtualization can also access and integrate data from different file formats, such as:
- CSV (Comma-Separated Values) – A commonly used format for storing data in simple table form.
- Excel (XLS/XLSX) – Widely used in businesses for data analysis and reporting.
- JSON (JavaScript Object Notation) – A data format frequently used in web-based applications and APIs.
Big Data Technologies
In the world of big data, virtualization can connect with large-scale data processing technologies, such as:
- Hadoop: An open-source framework used for storing and processing large-scale data.
- Apache Spark: A distributed computing technology that enables fast and efficient data processing.
Benefits of Virtualization
Faster Data Access: No need for physical data movement, which speeds up the analysis process.
Cost Efficiency: Businesses can reduce the need to store data in separate systems, leading to significant savings.
High Flexibility: This technology adapts well to various IT environments, whether on-premise or cloud-based.
Enhanced Security: Since data remains in its original source, the risk of data breaches is minimized.
Conclusion
Virtualization is an effective solution for managing data from multiple sources without physically relocating it. With support for relational databases, NoSQL, file formats such as CSV and JSON, and big data technologies like Hadoop and Spark, virtualization offers high flexibility in data integration and analysis. This technology is an ideal choice for companies looking to improve data management efficiency in the digital era.
If you want to optimize data management with virtualization technology, Dave is here to help! Try our service and experience seamless data access and integration on a single platform.